「AI (Artificial Intelligence)|人工智慧」穿梭在熙來攘往人海邊緣的電視牆、醫療院所不期而遇的角落、或熟識或陌生的網際社群,這個詞彙既琅琅上口卻又令人摸不著頭緒,不時還有特定職業恐被 AI 取代的街坊傳說。

上個月因緣際會第二次接觸 MIMIC III Database 而更接近資料科學了些,也透過書本、Workshop 和 On-Site Lectures 淺薄地進一步認識 AI。如今,透過我這般超級門外漢的眼睛,來聊聊什麼是 AI、以及他可能應用在哪些與醫療相關的層面。先從第二篇開始講起,因為第一篇的當刻心法尚未成熟、第三篇正在進行中;希望透過紀實分享拋磚,得到有興趣的人(玉)的一些回饋或是延伸可能性,我想是件蠻美的事。
Polanyi’s Paradox — “There is much more to our cognitive phenomenon which cannot be expressed or pictured correctly.” 我們懂的事情,比我們能表達出來的更多。這意味著,此悖論不只限制我們能告訴另一個人的事情,也為我們賦予機器智慧的能力做為佐證。
讓我們先來看看 AI 的演進:
第一波(1950–1960): 符號邏輯 (把人的思考邏輯放進電腦) — 由領域專家寫下決策邏輯,人類還沒辦法清楚理解自己的思考過程,那麼如何告訴電腦?第二波(1980–1990): 專家系統 (把人的所有知識放進電腦) — 由領域專家寫下經驗規則;但是,太多難題人類無法解答、寫成規則、以程式碼表示。
第三波(2010-present): 專家系統 (把人的所有看見放進電腦) — 由領域專家提供歷史資料。當今不再談 Logic, Theory; 而重視 data, network。
人工智慧的範疇很大,耳熟能詳的「機器學習 (Machine Learning, ML)」 、「深度學習 (Deep Learning, DL)」只是其中的子集合。Machine Learning 談的是 “Training a prediction machine by showing examples instead of programming it.” 可基於已知預測未知(不知道的事情為此處預測的定義,不一定是時序上的)的數學模型,給電腦很多例子就好、讓電腦自行學會,學會的方法就是機器學習。而 Deep learning 是 machine learning 的一種,可用在任何地方(如 Google 的服務)、Mapping 複雜的地方、講不出規則或無法定義的 (如書的推薦、判斷垃圾郵件),就是用機器學習,本質上是抓出歸納 Input 與 Output 的 non-linear 關聯再做 Mapping,要學的是哪些資料適合 Mapping。所有適合電腦做決策基礎的可歸入 AI,使用 data 找到規則的演算法 — based on data = machine learning; 自動作 feature engineering 是 deep learning。
目前多數產業用的還是 rule-based AI,請專家 (而不用data) 把規則寫出來,讓醫師把診斷的 Rule 講出來,比如 Retinopathy多大的尺寸算是出血點、亮度的變化、白斑多白多大塊等,但這絕不是件簡單的事,運作出的模型也通常比醫師不準,因為能講出來的規則都是簡化(還記得 Polanyi’s Paradox 嗎?),當寫成程式就更簡化了。而十年前最流行的 Classical machine learning 則讓醫師改為處理 feature extraction,譬如原先診斷的 rule 要描述得很精確,如出血點、轉折角度… 但是 Features 只需要講醫師會看什麼、大概要看哪裡、接著醫師提供 data 讓工程師寫 classification 程式,自動根據醫師決策的 feature 去從 data 學決策規則;準確度與醫師相較,可能有好有壞。

談到這裡,就能切入這次 ProSepsius 做的主題:DIC prediction Model in Sepsis Patients。因為使用的是 MIMIC (Medical Information Mart for Intensive Care) III Database (https://mimic.physionet.org/),我們處理的問題會拉到加護病房或重症的病人群體。

敗血症 (Sepsis) 是身體因應感染所產生的一系列會損害器官與組織並威脅生命的反應,每年約有 1,800 萬個病人產生嚴重的敗血症 (死亡率約 40–80%) ,是加護病房相當常見、且需被嚴肅處理的議題。

而這群敗血症病人後續產生血管內瀰漫性凝血 (Disseminated Intravascular Coagulation, DIC) 與否,對於病人的預後有顯著的影響。但是,目前缺乏有效的指標來預測此一凝血、溶血功能失調的疾病。
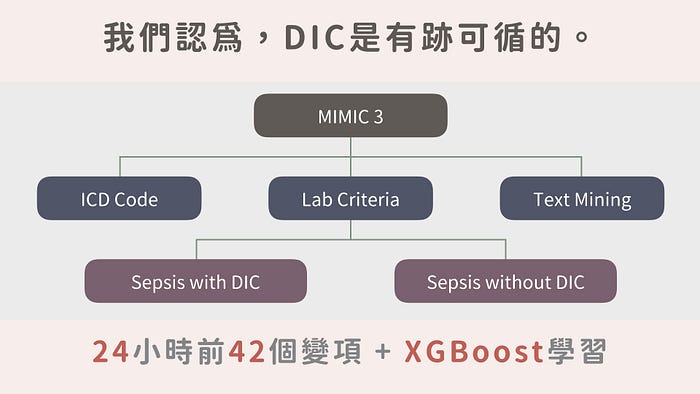
因此,我們從 MIMIC III Database 提取出敗血症病人,用 ICD code (符合 DIC 診斷)、Lab data (以目前診斷 DIC 的 PLT / PT / Fibrinogen / D-Dimer / Protein C activity / Antithrombin III 的計分方式)、Text mining (病歷中有提到 DIC 症狀的文字描述) 提取出發生 DIC的病人群體,篩選發生 DIC 前 24 小時共 42 個變項,以 XGBoost 方式、Stratified K-Fold Cross Validation 學習建模。
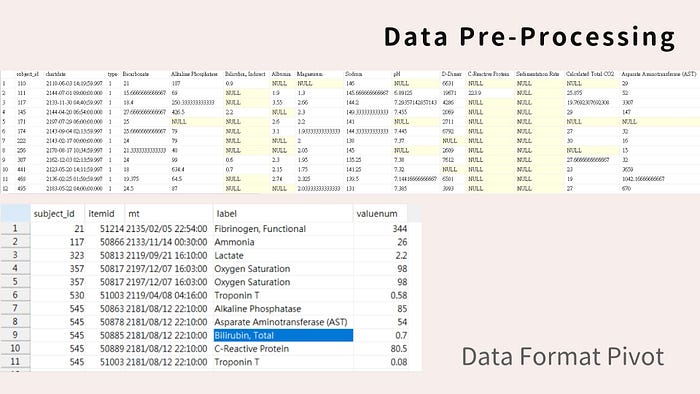
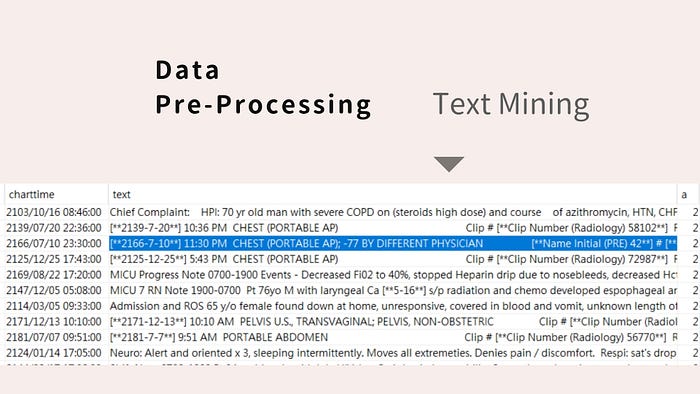
最終,我們找出了包含 INR、PLT、serum potassium、ALT等預測 DIC 發生趨勢的特定因子,希望這些發現與醫療資訊系統整合,未來能夠幫助我們早期預測敗血症病人發生 DIC 的機率,以利於在加護病房提供預防性的介入、找出造成 DIC 的原因、甚至作為照護指引修訂的參考。

技術面還是要請我們偉大的工程師來解釋更清楚,自己也還在發掘並定義問題、與吸收理論後應用到臨床實務面的培力之路上邁進,台灣往後的急重症資料庫建構成熟後,再回過頭來對資料處理的方法學及定義做修正可能會更有幫助與準確。之後應該要有更多搭配 Lectures 與應用上有更多結合的說明,讓想連結醫療與資料科學的朋友能更理解我們想做什麼、怎麼做、往後各自或共同的產出或許會對醫療有更多輔助的效益。不過,我很清楚渺小如我懂的只是皮毛而已,學習之路漫漫,但過程中結識奮鬥的朋友們總是最美麗的風景。

Reference: 《人工智慧在台灣》